Cutout / Random Erasing
Cutout / Random Erasing
Cutout7は2017年8月15日に、Random Erasing8は2017年8月16日と、ほぼ同時期にarXivに論文が公開されたほぼ同一の手法(!)で、モデルの正則化を目的とした新しいdata augmentationを提案しています。
同じく正則化を目的としたDropoutは全結合層には効果がありますが、CNNに対しては元々パラメータが少ないため効果が限定的でした。より重要な観点として、CNNの入力である画像は隣接画素に相関があるので、ランダムにdropしたとしてもその周りのピクセルで補間できてしまうため、正則化の効果が限定的でした。
これに対し、Cutout/Random Erasingでは入力画像をランダムなマスクで欠落させることで、より強い正則化の効果を作り出すことを狙いとしています。
上図の左がCutout、右がRandom Erasingにおけるdata augmentation結果例です(画像はそれぞれの論文から引用)。

Cutout
Cutoutでは、マスクの形よりもサイズが重要であるとの主張から、マスクの形状は単純なサイズ固定の正方形を利用し、そのマスクを画像のランダムな位置にかけて、その値を(データセットの?)平均値にしてしまいます。
より詳細には、マスクの中心位置を画像中のランダムな位置に設定し、その周りをマスクします。これにより、マスクの一部が画像からはみ出すケースが発生し、このようなあまりマスクをしすぎないケースが存在することも重要だと主張しています。
より明示的には、一定の確率でマスクを掛けないケースを許容することも考えられると記載されています(後述のRandom Erasingではそうなっています)。
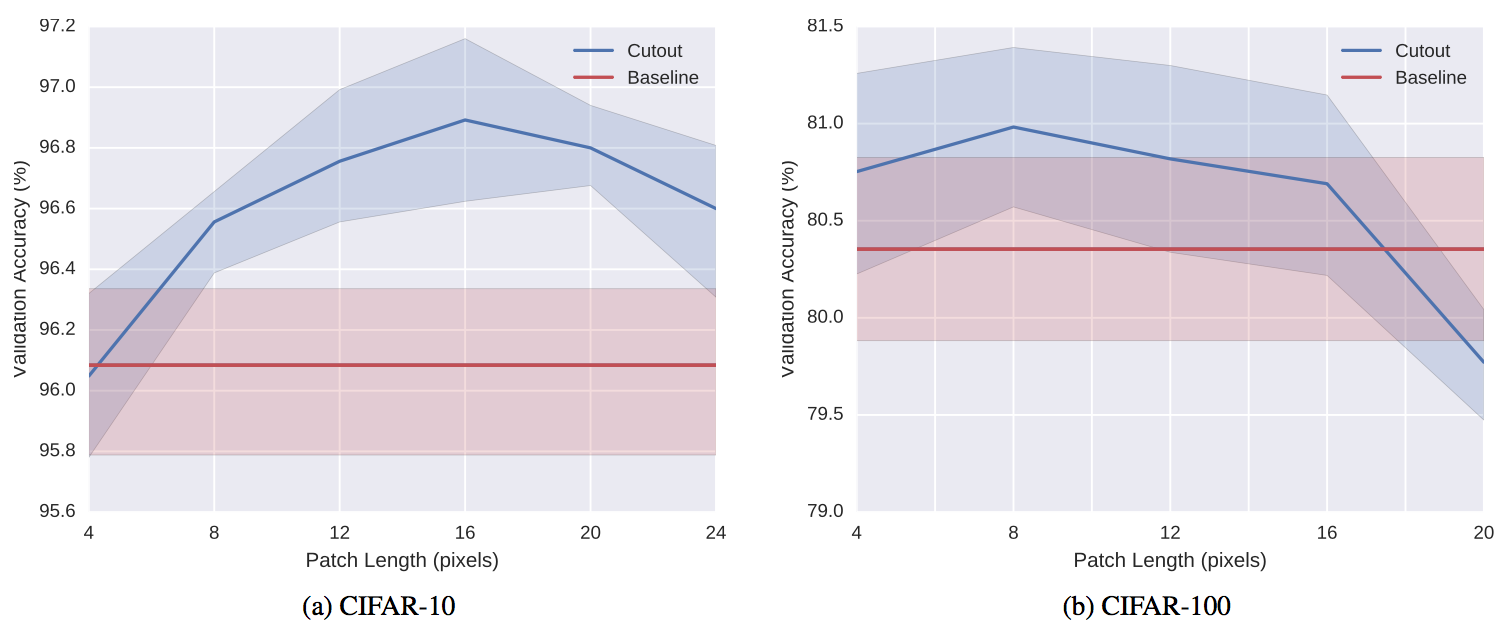
Cutoutの効果は上図(縦軸精度、横軸マスクのサイズ)のようにマスクのサイズに依存し、データセットとタスクによって最適なサイズが違うことが予想されます。
Random Erasing
Random Erasingでは、まず各画像に対しマスクを行うか行わないかをランダムに決定します。
マスクを行う場合には、まず画像中の何%をマスクするかを予め決められた範囲内からランダムに決定します。次に、同じく予め決められた範囲内でマスクのアスペクト比を決定します。最後にマスクの場所をランダムに決定し、マスク内の画素を0から255のランダムな値に変更します。
上記をベースとし、物体検出のように認識対象のBounding Boxが与えられるケースでは、それぞれの物体に対し、個別にRandom Erasingを行うことも提案しています。
具体的なパラメータとしては、実験的に、マスクをする確率を0.5、マスクの割合を2%〜40%、アスペクト比を0.3〜1/0.3とすることが推奨されています。
また、マスクでどのように画素を変更するかについて、ランダム、平均(Cutoutと同じ)、0、255の4種類のアプローチを比較しており、ランダムが一番良かったと報告されています(平均もほぼ同じ)。
Cutoutでは画像分類タスクのみでしか評価されていませんでしたが、Random Erasingの論文では、画像分類に加えて物体検出と人物照合タスクについても有効性が確認されています。
参考
https://qiita.com/yu4u/items/a9fc529c85534eca11e5