Intersection-over-Union(IoU)とは
Intersection-over-Union(IoU)とは
物体認識の分野で領域の一致具合を評価する手法である.
predicted bound box とground truth boxを合わせた領域bが, 目的となる領域g(ground truth box)がどれだけ含まれているかとなる.
IoU(b,g)=area(b∩g)/area(b∪g)


request python まとめ
what is request
requestsとはサードパーティ製のhttp通信を行うためのライブラリ これを使用すると、webサイトのデータのダウンロードやrestapiの使用が可能 install cmd pip install requests
example
ヤフーのニュース一覧ページのhtmlを取得 import requests url = "https://news.yahoo.co.jp/topics" r = requests.get(url) print(r.text)
urlから画像ダウンロード
import urllib.error import urllib.request headers = { "User-Agent": "Mozilla/5.0 (X11; Ubuntu; Linux x86_64; rv:47.0) Gecko/20100101 Firefox/47.0", }
def download_image(url, dst_path, headers): try: # request = urllib.request.Request(url=url, headers=headers) # data = urllib.request.urlopen(request)
data = urllib.request.urlopen(url,headers).read()
with open(dst_path, mode="wb") as f:
f.write(data)
except urllib.error.URLError as e:
print(e)
url = 'URL' dst_path = 'lena_square.png'
dst_dir = 'data/src'
dst_path = os.path.join(dst_dir, os.path.basename(url))
download_image(url, dst_path, headers)
urlからhtmlコンテンツダウンロード
coding:utf-8
import urllib.request
url = "URL" headers = { "User-Agent": "Mozilla/5.0 (X11; Ubuntu; Linux x86_64; rv:47.0) Gecko/20100101 Firefox/47.0", }
request = urllib.request.Request(url=url, headers=headers) response = urllib.request.urlopen(request) html = response.read().decode('utf-8') print(html)
参考
http://www.python.ambitious-engineer.com/archives/974#requests
imgaugライブラリを使った機械学習用のdata augmentation
install
通常版
sudo pip install imgaug
最新版
pip install git+https://github.com/aleju/imgaug
必要なもの
- six
- numpy
- scipy
- scikit-image (pip install -U scikit-image)
- OpenCV (i.e. cv2)
使い方
すべてのDA手法をお試しするならgenerate_example_images.pyを実行すればよし
DAの種類
kerasで実装できないものをまとめてみました。
ペッパー

ガウシアンノイズ

ソルト

ペッパー

ソルト&ペッパー

piece wise affine(区分積分アフィン?)

透視変換(perspective transform)

crop(トリミング)

平滑化フィルタ
median blur

gaussian blur

bilateral blur

averageblur

coarseシリーズ
coarse ソルト

coarse ペッパー

coarse Dropout

coarse ソルト&ペッパー

contrast normalization

frequency noisealpha

multiply (ピクセル演算)

参考
keras 学習済モデルの取り扱い全般まとめ
keras公式の学習済モデル読み込み方法
from keras.applications.inception_v3 import InceptionV3 InceptionV3 = InceptionV3(include_top=False, weights='imagenet', input_tensor=input_tensor)
kerasで利用可能なモデル
ImageNetで学習した重みをもつ画像分類のモデル:
- Xception
- VGG16
- VGG19
- ResNet50
- InceptionV3
- InceptionResNetV2
- MobileNet
- NASNet
参照 https://keras.io/ja/applications/
学習済モデルを利用した学習方法
- 重み読み込み版(finetuning) weights='imagenet'を指定
from keras.applications.inception_v3 import InceptionV3 InceptionV3 = InceptionV3(include_top=False, weights='imagenet', input_tensor=input_tensor)
- 重み読み込みなし版 weights='None'を指定
from keras.applications.inception_v3 import InceptionV3 InceptionV3 = InceptionV3(include_top=False, weights='None', input_tensor=input_tensor)
- オリジナルの学習済モデルの場合(finetuning)
model.load_weights("./weight.19-0.70.hdf5", by_name=True)
model.load_weights(filepath, by_name=False): (save_weightsによって作られた) モデルの重みをHDF5形式のファイルから読み込む
デフォルトはモデルの構造は不変であることが前提
(いくつかのレイヤーが共通した)異なる構造に対して重みを読み込む場合,by_name=Trueを使うことで,同名のレイヤーにのみ読み込み可能
学習モデルの保存方法
model.save_weights(os.path.join('PATH', 'InceptionV3_scratch2.h5'))
ModelCheckpointを使った各エポック終了後にモデルの保存のしかた
keras.callbacks.ModelCheckpoint(filepath, monitor='val_loss', verbose=0, save_best_only=False, save_weights_only=False, mode='auto', period=1)
引数
- filepath: モデルファイルを保存するパス.
- monitor: 監視する値.
- verbose: 冗長モード, 0 または 1.
- save_best_only: save_best_only=Trueの場合,監視しているデータによって最新の最良モデルが上書きされない.
- mode: {auto, min, max}の内の一つが選択されます.save_best_only=Trueならば,現在保存されているファイルを上書きするかは,監視されている値の最大化か最小化によって決定.
val_accの場合,この引数はmax
val_lossの場合はmin
autoモードでは,この傾向は自動的に監視されている値から推定します. * save_weights_only: Trueなら,モデルの重みが保存されます (model.save_weights(filepath)),そうでないなら,モデルの全体が保存されます (model.save(filepath)). * period: チェックポイント間の間隔(エポック数).
参考にしたもの
https://employment.en-japan.com/engineerhub/entry/2017/04/28/110000
ubuntu16.04でのTensorFlow環境構築でのメモ
TensorFlowのインストール
「libcupti-dev」を入れます。
sudo apt-get install libcupti-dev 「これはNVIDIA CUDAプロファイルツールインタフェースです。このライブラリは高度なプロファイリングのサポートを提供します。」だそうです。(TensorFlowより)
次にvirtualenvを入れます。これは入れといたほうがいいです(condaがあるならそれでいいですけど)。TensorFlowはバージョンアップするごとに仕様が少し変わるので、違うバージョンを試してみたいということは多々起こります。
一行目が2系用、二行目が3系用です。Pythonのバージョンに合わせて実行。
sudo apt-get install python-pip python-dev python-virtualenv sudo apt-get install python3-pip python3-dev python-virtualenv
インストール後は以下。こちらも一行目が2系、二行目が3系。
virtualenv --system-site-packages ~/tensorflow virtualenv --system-site-packages -p python3 ~/tensorflow
「~/tensorflow」のとこは別に自分の好きなディレクトリ名で結構ですが、まあ、これから変更する理由は特に無いと思います。
次に環境をアクティベートします。
source ~/tensorflow/bin/activate # bash, sh, ksh, or zsh source ~/tensorflow/bin/activate.csh # csh or tcsh
使っているターミナルに合わせて選んでください。ubuntuの入れたばかりならbashです。アクティベートされたらいよいよTensorFlowをインストール。
(tensorflow)$ pip install --upgrade tensorflow # for Python 2.7 (tensorflow)$ pip3 install --upgrade tensorflow # for Python 3.n (tensorflow)$ pip install --upgrade tensorflow-gpu # for Python 2.7 and GPU (tensorflow)$ pip3 install --upgrade tensorflow-gpu # for Python 3.n and GPU
TensorFlowが利用できるか確認 TensorFlowを利用するときはアクティベートが必要です。
以下のコマンドでできます。
source ~/tensorflow/bin/activate # bash, sh, ksh, or zsh source ~/tensorflow/bin/activate.csh # csh or tcsh
逆に終了する場合は
deactivate
参考にしたもの
data augementation : mixup
mixup1は、2つの訓練サンプルのペアを混合して新たな訓練サンプルを作成するdata augmentation手法の1つ
具体的には、データとラベルのペアから、下記の式により新たな訓練サンプル
を作成します。ここでラベル
はone-hot表現のベクトルになっているものとします。
は任意のベクトルやテンソルです。
ここで]は、ベータ分布
からのサンプリングにより取得し、αはハイパーパラメータとなります。特徴的なのは、データ
だけではなく、ラベル
も混合してしまう点です。
この定式化の解釈の参考記事:
http://www.inference.vc/mixup-data-dependent-data-augmentation/
実装
ジェネレータとして実装します。
https://github.com/yu4u/mixup-generator
import numpy as np
class MixupGenerator(): def __init__(self, X_train, y_train, batch_size=32, alpha=0.2, shuffle=True, datagen=None): self.X_train = X_train self.y_train = y_train self.batch_size = batch_size self.alpha = alpha self.shuffle = shuffle self.sample_num = len(X_train) self.datagen = datagen def __call__(self): while True: indexes = self.__get_exploration_order() itr_num = int(len(indexes) // (self.batch_size * 2)) for i in range(itr_num): batch_ids = indexes[i * self.batch_size * 2:(i + 1) * self.batch_size * 2] X, y = self.__data_generation(batch_ids) yield X, y def __get_exploration_order(self): indexes = np.arange(self.sample_num) if self.shuffle: np.random.shuffle(indexes) return indexes def __data_generation(self, batch_ids): _, h, w, c = self.X_train.shape _, class_num = self.y_train.shape X1 = self.X_train[batch_ids[:self.batch_size]] X2 = self.X_train[batch_ids[self.batch_size:]] y1 = self.y_train[batch_ids[:self.batch_size]] y2 = self.y_train[batch_ids[self.batch_size:]] l = np.random.beta(self.alpha, self.alpha, self.batch_size) X_l = l.reshape(self.batch_size, 1, 1, 1) y_l = l.reshape(self.batch_size, 1) X = X1 * X_l + X2 * (1 - X_l) y = y1 * y_l + y2 * (1 - y_l) if self.datagen: for i in range(self.batch_size): X[i] = self.datagen.random_transform(X[i]) return X, y
training_generator = MixoutGenerator(x_train, y_train)()で、訓練データとラベルの集合を引数としてジェネレータを取得し、x, y = next(training_generator)で学習用のバッチが取得できます。
CIFAR-10データセットを利用してmixupした例です。
Cutout / Random Erasing
Cutout / Random Erasing
Cutout7は2017年8月15日に、Random Erasing8は2017年8月16日と、ほぼ同時期にarXivに論文が公開されたほぼ同一の手法(!)で、モデルの正則化を目的とした新しいdata augmentationを提案しています。
同じく正則化を目的としたDropoutは全結合層には効果がありますが、CNNに対しては元々パラメータが少ないため効果が限定的でした。より重要な観点として、CNNの入力である画像は隣接画素に相関があるので、ランダムにdropしたとしてもその周りのピクセルで補間できてしまうため、正則化の効果が限定的でした。
これに対し、Cutout/Random Erasingでは入力画像をランダムなマスクで欠落させることで、より強い正則化の効果を作り出すことを狙いとしています。
上図の左がCutout、右がRandom Erasingにおけるdata augmentation結果例です(画像はそれぞれの論文から引用)。

Cutout
Cutoutでは、マスクの形よりもサイズが重要であるとの主張から、マスクの形状は単純なサイズ固定の正方形を利用し、そのマスクを画像のランダムな位置にかけて、その値を(データセットの?)平均値にしてしまいます。
より詳細には、マスクの中心位置を画像中のランダムな位置に設定し、その周りをマスクします。これにより、マスクの一部が画像からはみ出すケースが発生し、このようなあまりマスクをしすぎないケースが存在することも重要だと主張しています。
より明示的には、一定の確率でマスクを掛けないケースを許容することも考えられると記載されています(後述のRandom Erasingではそうなっています)。
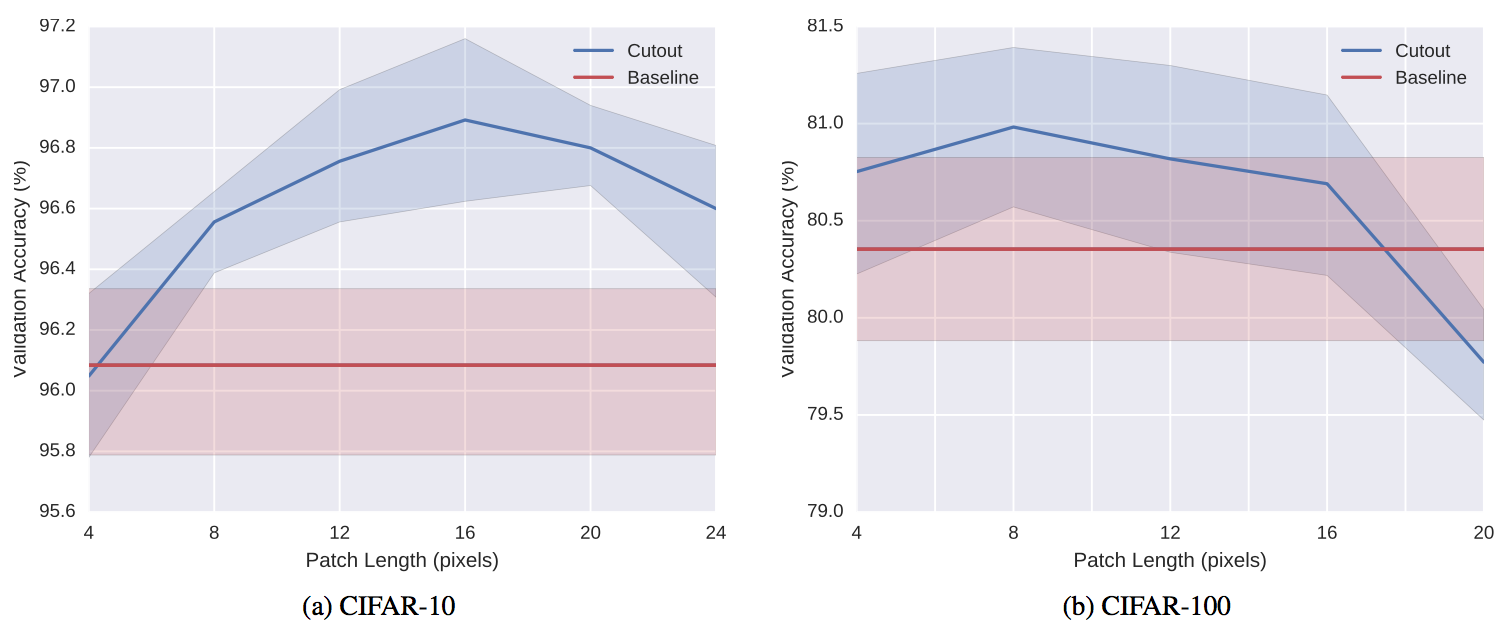
Cutoutの効果は上図(縦軸精度、横軸マスクのサイズ)のようにマスクのサイズに依存し、データセットとタスクによって最適なサイズが違うことが予想されます。
Random Erasing
Random Erasingでは、まず各画像に対しマスクを行うか行わないかをランダムに決定します。
マスクを行う場合には、まず画像中の何%をマスクするかを予め決められた範囲内からランダムに決定します。次に、同じく予め決められた範囲内でマスクのアスペクト比を決定します。最後にマスクの場所をランダムに決定し、マスク内の画素を0から255のランダムな値に変更します。
上記をベースとし、物体検出のように認識対象のBounding Boxが与えられるケースでは、それぞれの物体に対し、個別にRandom Erasingを行うことも提案しています。
具体的なパラメータとしては、実験的に、マスクをする確率を0.5、マスクの割合を2%〜40%、アスペクト比を0.3〜1/0.3とすることが推奨されています。
また、マスクでどのように画素を変更するかについて、ランダム、平均(Cutoutと同じ)、0、255の4種類のアプローチを比較しており、ランダムが一番良かったと報告されています(平均もほぼ同じ)。
Cutoutでは画像分類タスクのみでしか評価されていませんでしたが、Random Erasingの論文では、画像分類に加えて物体検出と人物照合タスクについても有効性が確認されています。
参考
https://qiita.com/yu4u/items/a9fc529c85534eca11e5