sckit-learn データセットを使った機械学習 分類編2 分類器を使った分類
用いる分類器の種類
・k近傍法
・サポートベクターマシン(線形)
・サポートベクターマシン(ガウシアンカーネル)
・決定木
・ランダムフォレスト
・AdaBoost
・ナイーブベイズ
・線形判別分析
・二次判別分析
サポートベクターマシン(Support Vector Machine:SVM)は2クラス分類識別器の一種ある。
その大きな特徴として次の三つがあげられる。
1.マージン最大化という方針で識別平面を決定するので高い汎化能力が期待できる。
2.学習がラグランジュ未定乗数法により二次計画問題に帰着され、局所最適解が必ず広域最適解となる。
3.識別対象の空間に対する事前知識を反映した特徴空間を定義することで、その特徴空間上で線形識別を行える。 さらにその特徴空間上での内積を表したカーネルと呼ばれる関数を定義することにより、明示的に特徴空間への 変換を示す必要がない。
from skleran import svm classifier = svm.SVC(C=1.0, gamma=0.001)
決定木
データを複数クラスに分類する教師あり学習の1つ.
樹木モデルと呼ばれる木構造を利用した分類アルゴリズムです.
樹木モデルは,分類を実現するための分岐処理の集まり.
決定木のメリットは,分類ルールを樹木モデルとして可視化できるため,分類結果の解釈が比較的容易である点です.
デメリットは,過学習してしまう場合がある.
また,扱うデータの特性によっては,樹木モデルを生成することが難しいケースがある.
import matplotlib.pyplot as plt import numpy as np from sklearn import datasets from sklearn import tree from sklearn import metrics #3 and 8 setting position flag_3_8 = (digits.target == 3) + (digits.target == 8) #get data of 3 and 8 #.target[]でラベル,.images[]で画像を取得 images = digits.images[flag_3_8] labels = digits.target[flag_3_8] #3と8の画像データを一次元化 images = images.reshape(images.shape[0], -1) #create cllasifier n_sample = len(flag_3_8[flag_3_8]) train_size = int(n_sample * 3 / 5) #分類器:決定木を生成 classifier = tree.DecisionTreeClassifier() #classifier.fit()で生成した分類器に学習データを与えて学習を実行 classifier.fit(images[:train_size], labels[:train_size]) #性能評価 #正解ラベルとしてテストデータのラベルを取り出している expected = labels[train_size:] #分類の実行(テストデータを与えて分類結果(予測したラベル)を取得している) predicted = classifier.predict(images[train_size:]) #accuracy_score()によって正答率を計算 print('accuracy:\n', metrics.accuracy_score(expected, predicted))
ランダムフォレスト
アンサンブル学習と呼ばれる学習法のひとつ.アンサンブル学習とは,いくつかの性能の低い分類器を組み合わせて,ひとつの性能の高い分類器を作る手法です.性能の低い分類器は決まったものがあるわけではなく,適宜選択の必要がある.
アンサンブル学習のイメージは,弱分類器の多数決.
下記の2つの生成方法に分けることができる.
バギング
学習データを抜けや重複を許して複数個のグループに分割し,学習データのグループごとに弱分類化を生成する手法です.分類時は,各弱分類器の出力した分類結果の多数決を取ります.
ブースティング
複数の弱分類器を用意し,重み付きの多数決で分類を実現する方法.その重みも学習によって決定します,難易度の高い学習データを正しく分類できる弱分類器の判別結果が重視されるように重みを更新していきます.
ランダムフォレストは,バギングに分類されるアルゴリズム.
学習データ全体の中から重複や欠落を許して複数個の学習データセットを抽出し,その一部の属性を使って決定木を生成します.
判別処理が高速で学習データのノイズにも強いというメリットがある.分類だけでなく回帰やクラスタリングにも使える.
ただし,学習データ数が少ない場合は過学習になる傾向がある.
ランダムフォレストは決定木を複数組み合わせて、各決定木の予測結果を多数決することによって結果を得る.
以下アルゴリズム
①ランダムにデータを抽出
②決定木を成長させる
③1,2ステップを指定回繰り返す
予測結果を多数決することによって分類閾値(ラベル)を決定
ランダムフォレストはパラメータが非常に簡単になるという利点があります.主要なパラメータはサンプリング数と決定木を成長させる際に使用する特徴量の数だけです.
決定木の特徴量数は一般的にサンプル数をnとしたときにn‾√n にすると良いと言われている.
from sklearn import ensemble classifier _ ensemble.RandomForestClassifier(n_estimator_20, max_depth_3, criterion="gini”)
AdaBoost
アンサンブル学習の一つ.ブースティングに分類されるアルゴリズム.
弱識別機の適用させ,誤分類してしまったものの重みを増やす.
そして,次にその重みがついたものを優先的にみて,分類.ということを繰り返す.
参考:
http://www.kameda-lab.org/lecture/2011-tsukubagrad-PRML/20111004_AIST_Makita.pdf
from sklearn import ensemble estimator = tree.DecisionTreeClassifier(max_depth=3) classifier _ ensemble.AdaBoostClassifier(base_estmator=estimator, n_estimator=20)
Matplotlibで画像を表示
from PIL import Image from matplotlib import pylab as plt # 画像の読み込み img = np.array( Image.open('####.jpg') ) # 画像の表示 plt.imshow( img )
sckit-learn データセットを使った機械学習 分類編1
digitsデータセット読み込み表示
from sklearn import datasets digits = datasets.load_digits() #読み込みデータ表示 #digits.dataが入力データ #digits.targetが判別結果 print(digits.data) [[ 0. 0. 5. ..., 0. 0. 0.] [ 0. 0. 0. ..., 10. 0. 0.] [ 0. 0. 0. ..., 16. 9. 0.] ..., [ 0. 0. 1. ..., 6. 0. 0.] [ 0. 0. 2. ..., 12. 0. 0.] [ 0. 0. 10. ..., 12. 1. 0.]] digits.target array([0, 1, 2, ..., 8, 9, 8]) #画像形式に変換して2行5列に表示 import matplotlib.pyplot as plt #.target[:10]で9までのラベル,.images[:10]で9までの画像を取得 for label, img in zip(digits.target[:10], digits.images[:10]): plt.subplot(2, 5, label + 1) plt.axis('off') plt.imshow(img, cmap=plt.cm.gray_r, interpolation='nearest') plt.title('Digit: {0}'.format(label)) plt.show()

python zip( )の使いかた
リスト内包表記
plt.legend() matplotlib by python で凡例
. label=キーワード引数を使う場合
プロットをする際にlabel=キーワード引数で結びつけるラベルを渡すことができます。 結びつけたら、あとはplt.legend関数を呼び出すだけで凡例がグラフにプロットされます。

2. plt.legend()関数でartistとラベルを対応付ける
plt.plot()関数はArtistクラスのインスタンスのリストを返します。 これを受け取ってplt.legend()関数に渡すことでもラベルを結びつけることができます。
以下のことが成立することを確かめておきましょう。
凡例の位置調節
凡例の位置が他のプロットとかぶってしまう場合にはloc=キーワード引数を渡すことで 好きな位置に移すことができます。
プロットと被る

凡例の位置を左上(upper left)に置く

あるいは右下(lower right)に置く

numpy .arange データ生成
numpyの.arangeでデータを生成する
0,1,2,3...とか1,3,5,7のようなデータを作る方法
start, step, dtypeは省略可能でstartを省略すると0からになる。
how to use
arange([start],stop,[step],[dtype])
start, step, dtypeは省略可能でstartを省略すると0からになる。
In [1]: import numpy as np In [2]: X = np.arange(10) In [3]: print X [0 1 2 3 4 5 6 7 8 9] In [4]: type(X) Out[4]: numpy.ndarray In [5]: X.dtype Out[5]: dtype('int32')
dtypeを省略した場合は、10のように整数で指定するとint32になり、10.のように浮動小数点で指定するとfloat64になる。
dtype=np.float32のように指定すると、ほしい型でデータが作成される。
In [15]: X = np.arange(10) In [16]: print X.dtype int32 In [17]: X = np.arange(10.) In [18]: print X.dtype float64 In [19]: X = np.arange(10.,dtype=np.float32) In [20]: print X.dtype float32
start,stop,stepを指定した時の例は下記の通り。
In [22]: X = np.arange(1,10) In [23]: print X [1 2 3 4 5 6 7 8 9] In [24]: X = np.arange(1,10,2) In [25]: print X [1 3 5 7 9] In [26]: X = np.arange(9,0,-2) In [27]: print X [9 7 5 3 1]
rangeとxrangeについて
ちなみにnumpyのarangeではなく、rangeを使うとnumpy arrayではなくlistになるので注意。
list Yをnumpy arrayにしたいときは、np.array(Y)とするとよい。
numpy arrayの変数Xにlist Yを代入してもnumpy arrayにはならない(X=Y)。
また、xrangeを使った場合は、generatorが生成される。実際の値を取得したいときは、for文で使うかlist(Z)のようにする。
In [6]: Y = range(10) In [7]: print Y [0, 1, 2, 3, 4, 5, 6, 7, 8, 9] In [8]: type(Y) Out[8]: list In [9]: Z = xrange(10) In [10]: print Z xrange(10) In [11]: type(Z) Out[11]: xrange In [12]: list(Z) Out[12]: [0, 1, 2, 3, 4, 5, 6, 7, 8, 9]
rangeとxrangeの違いは、rangeが一度にlistが生成されるのに対し、xrangeは1 loopに1回ずつ値が生成される。for文の途中でloopを抜けるような処理の場合に無駄な値の生成がなくなる。生成するlistが大きい場合はメモリと時間の節約になる。
In [13]: timeit for i in range(1000000): pass 10 loops, best of 3: 36.3 ms per loop In [14]: timeit for i in xrange(1000000): pass 100 loops, best of 3: 16.4 ms per loop
scatter plot by matplotlib
matplotlib.pyplot.scatter の概要
matplotlib には、散布図を描画するメソッドとして、matplotlib.pyplot.scatter が用意されてます。
matplotlib.pyplot.scatter の使い方
matplotlib.pyplot.scatter の主要な引数
| x, y | グラフに出力するデータ |
|---|---|
| s | サイズ (デフォルト値: 20) |
| c | 色、または、連続した色の値 |
| marker | マーカーの形 (デフォルト値: ‘o’= 円) |
| cmap | カラーマップ。c が float 型の場合のみ利用可能です。 |
| norm | c を float 型の配列を指定した場合のみ有効。正規化を行う場合の Normalize インスタンスを指定。 |
| vmin, vmax | 正規化時の最大、最小値。 指定しない場合、データの最大・最小値となります。norm にインスタンスを指定した場合、vmin, vmax の指定は無視されます。 |
| alpha | 透明度。0(透明)~1(不透明)の間の数値を指定。 |
| linewidths | 線の太さ。 |
| edgecolors | 線の色。 |
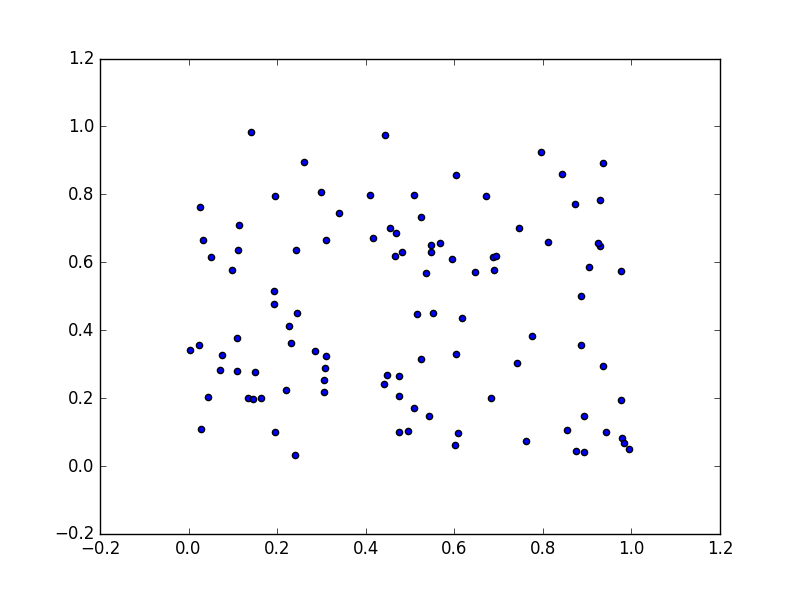
グラフの出力例
以下例では、100 個 × 2 軸の乱数を2次元座標上にプロットします。
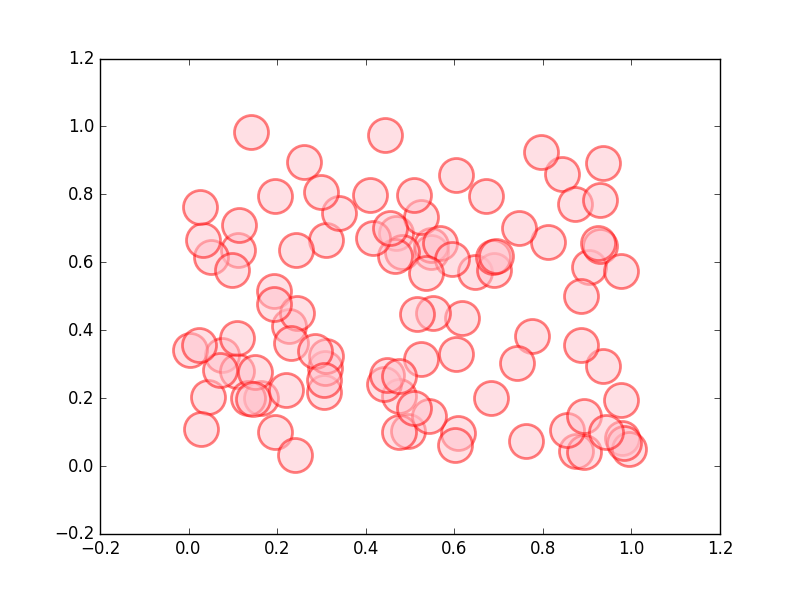
サイズ、色、不透明度、線のサイズ、色を指定
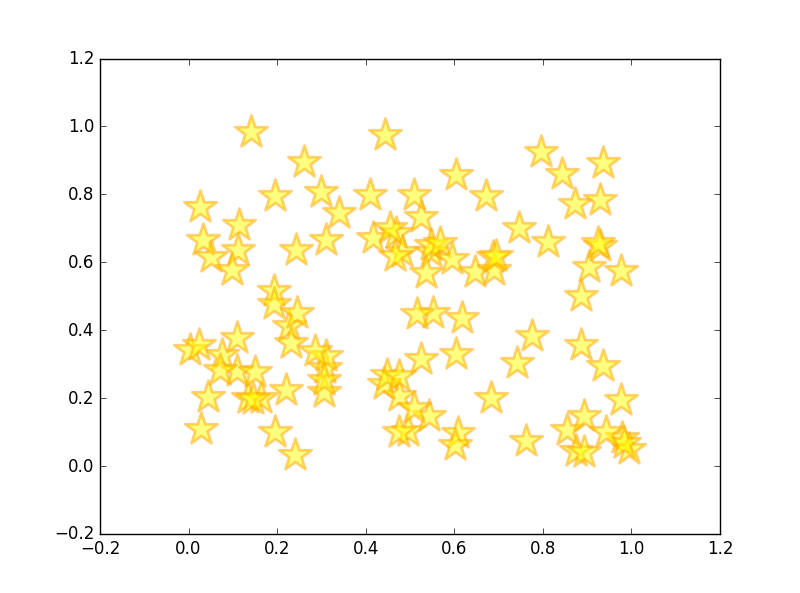
マーカーを指定 (星印)
グラフのタイトル、X 軸、Y 軸の名前 (ラベル)、グリッド線を表示
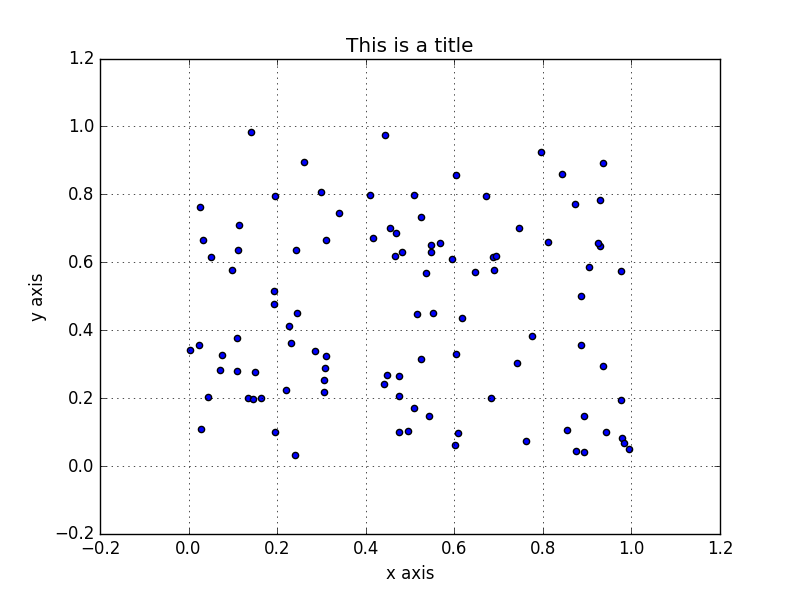
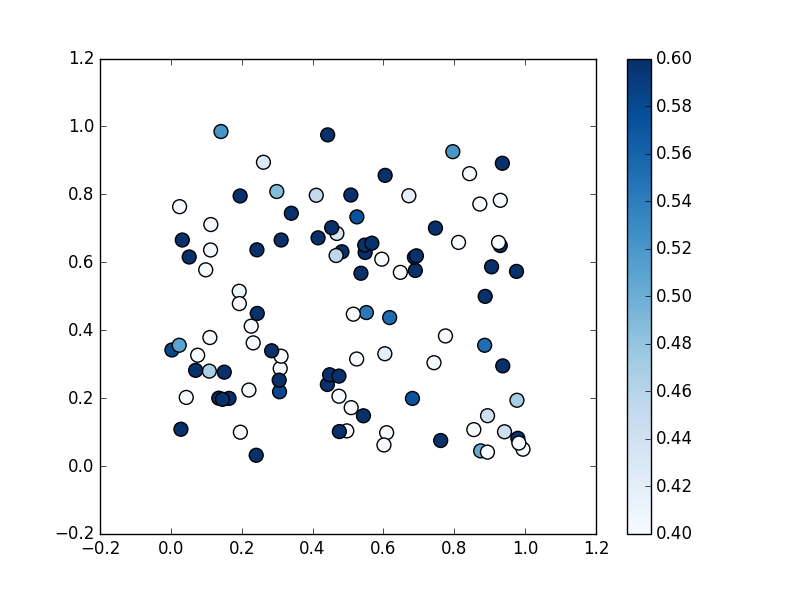
カラーマップを指定して、値に応じてマーカーを着色
引数 s の値の大小に応じて、色の濃淡やグラデーションで表現することができます。
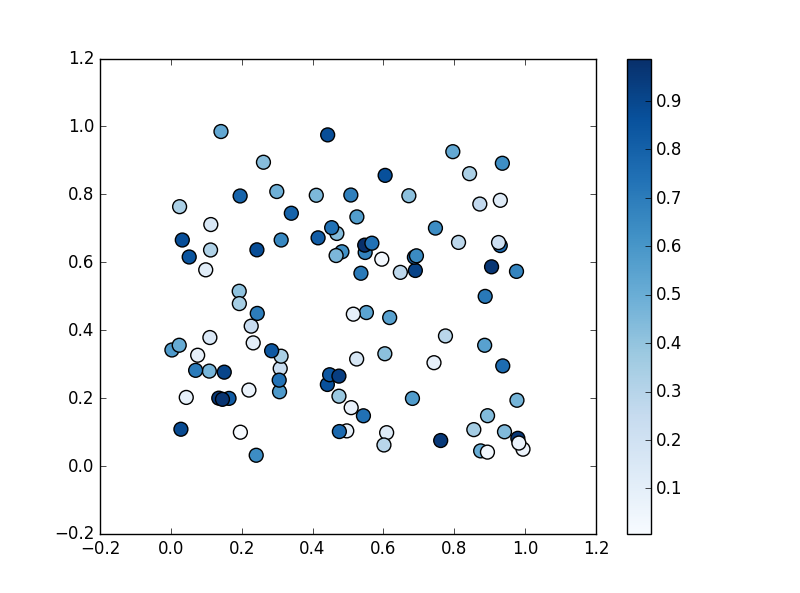
上記に加えて正規化における最大値 (0.6)、最小値 (0.4) を指定
(右側の凡例の目盛が変わっているのがわかるかと思います)