ubuntu16.04でのTensorFlow環境構築でのメモ
TensorFlowのインストール
「libcupti-dev」を入れます。
sudo apt-get install libcupti-dev 「これはNVIDIA CUDAプロファイルツールインタフェースです。このライブラリは高度なプロファイリングのサポートを提供します。」だそうです。(TensorFlowより)
次にvirtualenvを入れます。これは入れといたほうがいいです(condaがあるならそれでいいですけど)。TensorFlowはバージョンアップするごとに仕様が少し変わるので、違うバージョンを試してみたいということは多々起こります。
一行目が2系用、二行目が3系用です。Pythonのバージョンに合わせて実行。
sudo apt-get install python-pip python-dev python-virtualenv sudo apt-get install python3-pip python3-dev python-virtualenv
インストール後は以下。こちらも一行目が2系、二行目が3系。
virtualenv --system-site-packages ~/tensorflow virtualenv --system-site-packages -p python3 ~/tensorflow
「~/tensorflow」のとこは別に自分の好きなディレクトリ名で結構ですが、まあ、これから変更する理由は特に無いと思います。
次に環境をアクティベートします。
source ~/tensorflow/bin/activate # bash, sh, ksh, or zsh source ~/tensorflow/bin/activate.csh # csh or tcsh
使っているターミナルに合わせて選んでください。ubuntuの入れたばかりならbashです。アクティベートされたらいよいよTensorFlowをインストール。
(tensorflow)$ pip install --upgrade tensorflow # for Python 2.7 (tensorflow)$ pip3 install --upgrade tensorflow # for Python 3.n (tensorflow)$ pip install --upgrade tensorflow-gpu # for Python 2.7 and GPU (tensorflow)$ pip3 install --upgrade tensorflow-gpu # for Python 3.n and GPU
TensorFlowが利用できるか確認 TensorFlowを利用するときはアクティベートが必要です。
以下のコマンドでできます。
source ~/tensorflow/bin/activate # bash, sh, ksh, or zsh source ~/tensorflow/bin/activate.csh # csh or tcsh
逆に終了する場合は
deactivate
参考にしたもの
data augementation : mixup
mixup1は、2つの訓練サンプルのペアを混合して新たな訓練サンプルを作成するdata augmentation手法の1つ
具体的には、データとラベルのペアから、下記の式により新たな訓練サンプル
を作成します。ここでラベル
はone-hot表現のベクトルになっているものとします。
は任意のベクトルやテンソルです。
ここで]は、ベータ分布
からのサンプリングにより取得し、αはハイパーパラメータとなります。特徴的なのは、データ
だけではなく、ラベル
も混合してしまう点です。
この定式化の解釈の参考記事:
http://www.inference.vc/mixup-data-dependent-data-augmentation/
実装
ジェネレータとして実装します。
https://github.com/yu4u/mixup-generator
import numpy as np
class MixupGenerator(): def __init__(self, X_train, y_train, batch_size=32, alpha=0.2, shuffle=True, datagen=None): self.X_train = X_train self.y_train = y_train self.batch_size = batch_size self.alpha = alpha self.shuffle = shuffle self.sample_num = len(X_train) self.datagen = datagen def __call__(self): while True: indexes = self.__get_exploration_order() itr_num = int(len(indexes) // (self.batch_size * 2)) for i in range(itr_num): batch_ids = indexes[i * self.batch_size * 2:(i + 1) * self.batch_size * 2] X, y = self.__data_generation(batch_ids) yield X, y def __get_exploration_order(self): indexes = np.arange(self.sample_num) if self.shuffle: np.random.shuffle(indexes) return indexes def __data_generation(self, batch_ids): _, h, w, c = self.X_train.shape _, class_num = self.y_train.shape X1 = self.X_train[batch_ids[:self.batch_size]] X2 = self.X_train[batch_ids[self.batch_size:]] y1 = self.y_train[batch_ids[:self.batch_size]] y2 = self.y_train[batch_ids[self.batch_size:]] l = np.random.beta(self.alpha, self.alpha, self.batch_size) X_l = l.reshape(self.batch_size, 1, 1, 1) y_l = l.reshape(self.batch_size, 1) X = X1 * X_l + X2 * (1 - X_l) y = y1 * y_l + y2 * (1 - y_l) if self.datagen: for i in range(self.batch_size): X[i] = self.datagen.random_transform(X[i]) return X, y
training_generator = MixoutGenerator(x_train, y_train)()で、訓練データとラベルの集合を引数としてジェネレータを取得し、x, y = next(training_generator)で学習用のバッチが取得できます。
CIFAR-10データセットを利用してmixupした例です。
Cutout / Random Erasing
Cutout / Random Erasing
Cutout7は2017年8月15日に、Random Erasing8は2017年8月16日と、ほぼ同時期にarXivに論文が公開されたほぼ同一の手法(!)で、モデルの正則化を目的とした新しいdata augmentationを提案しています。
同じく正則化を目的としたDropoutは全結合層には効果がありますが、CNNに対しては元々パラメータが少ないため効果が限定的でした。より重要な観点として、CNNの入力である画像は隣接画素に相関があるので、ランダムにdropしたとしてもその周りのピクセルで補間できてしまうため、正則化の効果が限定的でした。
これに対し、Cutout/Random Erasingでは入力画像をランダムなマスクで欠落させることで、より強い正則化の効果を作り出すことを狙いとしています。
上図の左がCutout、右がRandom Erasingにおけるdata augmentation結果例です(画像はそれぞれの論文から引用)。

Cutout
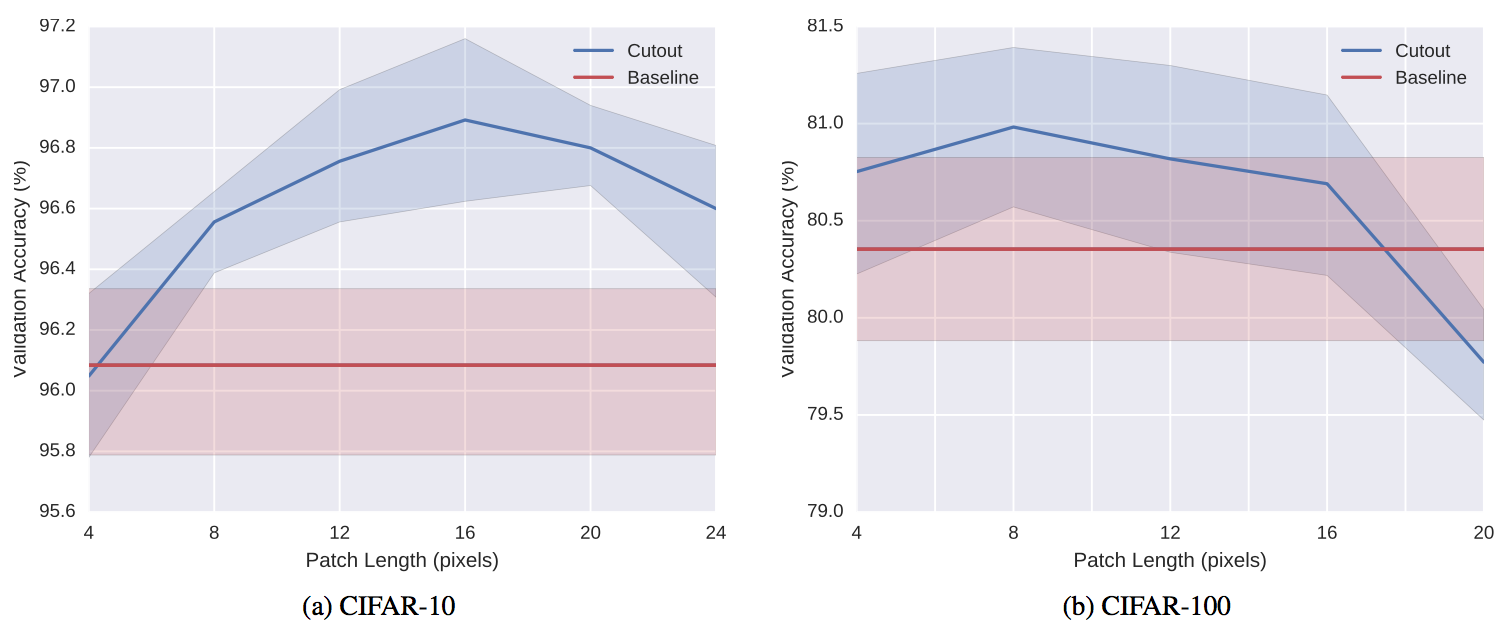
Cutoutでは、マスクの形よりもサイズが重要であるとの主張から、マスクの形状は単純なサイズ固定の正方形を利用し、そのマスクを画像のランダムな位置にかけて、その値を(データセットの?)平均値にしてしまいます。
より詳細には、マスクの中心位置を画像中のランダムな位置に設定し、その周りをマスクします。これにより、マスクの一部が画像からはみ出すケースが発生し、このようなあまりマスクをしすぎないケースが存在することも重要だと主張しています。
より明示的には、一定の確率でマスクを掛けないケースを許容することも考えられると記載されています(後述のRandom Erasingではそうなっています)。
Cutoutの効果は上図(縦軸精度、横軸マスクのサイズ)のようにマスクのサイズに依存し、データセットとタスクによって最適なサイズが違うことが予想されます。
Random Erasing
Random Erasingでは、まず各画像に対しマスクを行うか行わないかをランダムに決定します。
マスクを行う場合には、まず画像中の何%をマスクするかを予め決められた範囲内からランダムに決定します。次に、同じく予め決められた範囲内でマスクのアスペクト比を決定します。最後にマスクの場所をランダムに決定し、マスク内の画素を0から255のランダムな値に変更します。
上記をベースとし、物体検出のように認識対象のBounding Boxが与えられるケースでは、それぞれの物体に対し、個別にRandom Erasingを行うことも提案しています。
具体的なパラメータとしては、実験的に、マスクをする確率を0.5、マスクの割合を2%〜40%、アスペクト比を0.3〜1/0.3とすることが推奨されています。
また、マスクでどのように画素を変更するかについて、ランダム、平均(Cutoutと同じ)、0、255の4種類のアプローチを比較しており、ランダムが一番良かったと報告されています(平均もほぼ同じ)。
Cutoutでは画像分類タスクのみでしか評価されていませんでしたが、Random Erasingの論文では、画像分類に加えて物体検出と人物照合タスクについても有効性が確認されています。
参考
https://qiita.com/yu4u/items/a9fc529c85534eca11e5
Shake-Shake
Shake-Shake4 5はResNetをベースとし、テンソルに対するdata augmentationを行うことで、正則化を実現する手法です。通常data augmentationは画像に対して行われますが、中間層の出力テンソル(特徴ベクトル)に対してもdata augmentationを行うことが有効であろうというのが基本的なアイディアになります。
下記にShake-Shakeで利用される番目のresidual unitの構成を示します。
上記のようにShake-Shakeでは、residual unit内の畳み込みを2つに分岐させ、それらを一様乱数によって混ぜ合わせるということを行います。直感的には、画像ドメインに対するdata augmentationにおいてランダムクロッピングを行うことで、その画像内に含まれている物体の割合が変動してもロバストな認識ができるように学習ができるように、特徴レベルにおいても各特徴の割合が変動してもロバストな認識ができるようにしていると解釈することができます。
興味深いのは、backward時には、forward時の乱数とは異なる一様乱数を利用するということです。テスト時には、乱数の期待値である0.5を固定で利用してforwardを行います。
論文中では、上記のとを、0.5固定にしたり、それぞれ同じ値を利用したりする組み合わせを網羅的に検証しており、どちらも独立してランダムに (shake) する形が良いと結論付けています。
BackwardでのShakeは、residual unit毎に、learning rateをランダムにスケーリングしているような効果があり、SGDにおいて最適解に辿り着く確率を上げているのではないでしょうか(※個人の感想です)。

とは、バッチ単位で同一にするか、画像単位で独立に決定するかの2通りが考えられますが、こちらは画像単位で独立に決定するほうが良いと実験的に示されています。
これらの外乱効果は、ニューラルネットからすると迷惑限りないことですが、結果として強い正則化の効果をもたらし、既存手法に対しかなりの高精度化を実現できています。
なお、Shake-Shakeの学習で特徴的な点として、学習率の減衰をcosine関数で制御6し、通常300エポックかけて学習を行うところを、1800エポックかけてじっくりと学習することが挙げられます。これはShake-Shakeの効果により、擬似的に学習データが非常に大量にあるような状態となっているため、長時間の学習が有効であるためと考えられます。
webサービスを使った画像の二値化
PSによるpngの2値化
- PS起動
- 「イメージ」→「色調補正」→「2階調化」を選択
- 2階調化パネルの設定:しきい値設定
- finish 保存